

The act of processing data, which requires a lot of memory consumption, needs many physical machines to enable it. That is not always possible in the real world. Even the largest data centers in the early 2000s, despite having huge machine setups, still had the question of how the data could be split across these machines to conduct computation.
In today’s data-driven world, algorithms and applications are constantly collecting data, resulting in huge volumes of data. The big challenge is how to process this massive amount of data with speed and efficiency, and without sacrificing meaningful insights. To facilitate this, a programming model named MapReduce was initiated.
What is MapReduce?
MapReduce is a programming paradigm that allows us to perform distributed and parallel processing on large data sets in a distributed environment.
MapReduce facilitates concurrent processing by splitting petabytes of data into smaller chunks and processing them in parallel on commodity servers. In the end, it aggregates all the data from multiple servers to return a consolidated output back to the application.
MapReduce program works in two phases: Map and Reduce. Map tasks deal with splitting and mapping data, while Reduce tasks shuffle and reduce the data. The input to each phase is key-value pairs, which are then sorted out by the map and reduce functions.
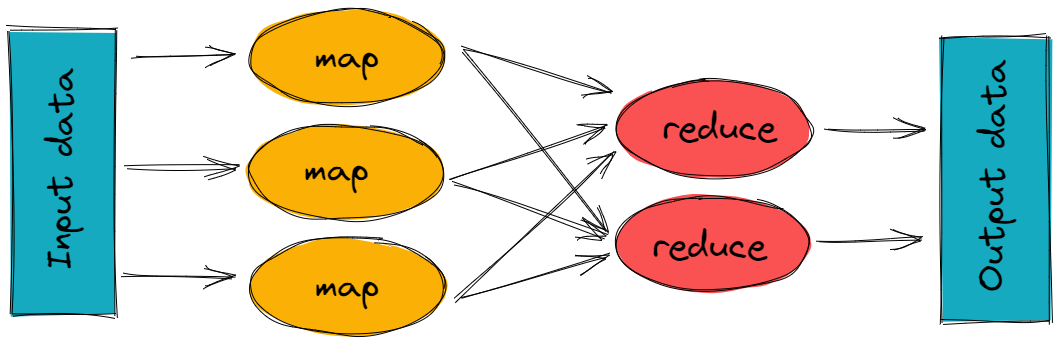
MapReduce programming offers several benefits to help gain valuable insights from big data:
- Scalability - Businesses can process petabytes of data
- Flexibility - It enables easier access to multiple sources of data and multiple types of data
- Speed - With parallel processing and minimal data movement, it offers fast processing of massive amounts of data
- Simple - Developers can write code in a choice of languages, including Java, C++, and Python

Try this exercise. Is this statement true or false?
Mapper step in MapReduce shuffles the input data.
Press true if you believe the statement is correct, or false otherwise.
What is Hadoop?
MapReduce is a component of the Apache Hadoop ecosystem, a framework that enhances massive data processing. Other components of Apache Hadoop include Hadoop Distributed File System (HDFS), Yarn and Apache Pig.
Some organizations rely on public cloud services for Hadoop and MapReduce, which offer enormous scalability with minimal capital costs or maintenance overhead.
For example, Amazon Web Services (AWS) provides Hadoop as a service through its Amazon Elastic MapReduce. Microsoft Azure offers its HDInsight service, which enables users to provision Hadoop, Apache Spark, and other clusters for data processing tasks. Google Cloud Platform provides its Cloud Dataproc service to run Spark and Hadoop clusters.

Example of MapReduce
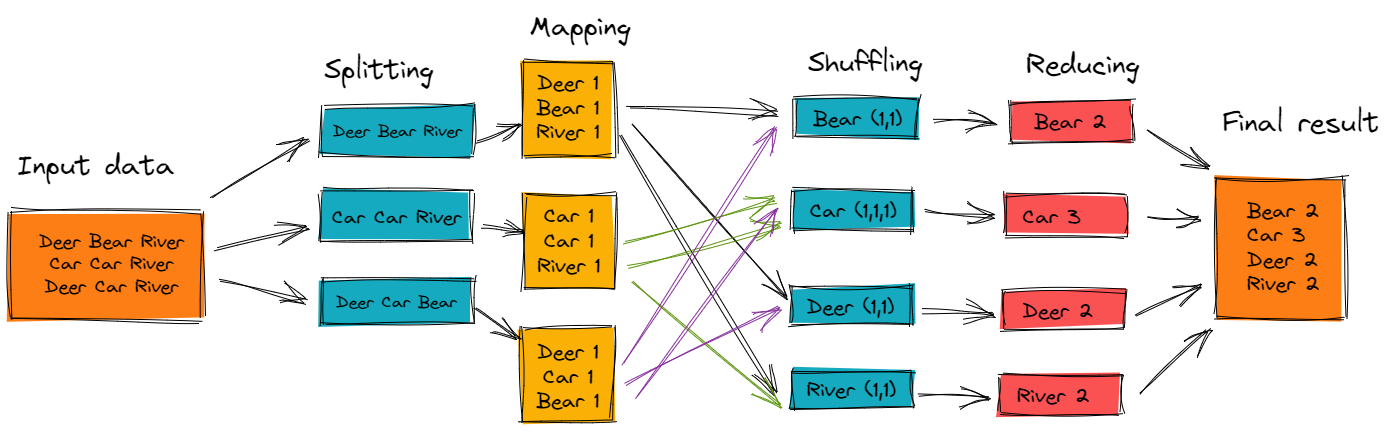
You can better understand, how MapReduce works by taking an example where we would have a text file called example.txt whose contents are:
Deer, Bear, River, Car, Car, River, Deer, Car, Bear
Now, we can perform a word count on the sample.txt using MapReduce. So, we will be finding unique words and the number of occurrences of those unique words.
- Divide the input into three splits as shown in the diagram. This will distribute the work among all the map nodes
- Tokenize the words in each of the mappers and give a hardcoded value (1) to each of the tokens or words
- A list of key-value pairs is created where the key is nothing but the individual words and the value is one. So, for (Deer Bear River) we have — Deer, 1; Bear, 1; River, 1
- Sorting and shuffling happen so that all the tuples with the same key are sent to the corresponding reducer
- After the sorting and shuffling phase, each reducer will have a unique key and a list of values corresponding to that very key. For example, Bear, [1,1]; Car, [1,1,1]...
- Each Reducer counts the values which are present in that list of values, and gives the final output as — Bear, 2
- All the output key/value pairs are collected and written in the output file
Code examples of MapReduce
Let's take the same example with the file sample.txt and code it into a program that will perform MapReduce. For the purpose of this example, the code will be written in Java, but MapReduce programs can be written in any language.
The entire MapReduce program can be fundamentally divided into three parts:
- Mapper Code The Map class extends the class Mapper which is already defined in the MapReduce Framework, and we define the input/output types.
1class Map {
2public:
3 void map(LongWritable &key, Text &value, Context &context) {
4 std::string line = value.toString();
5 std::istringstream tokenizer(line);
6 std::string token;
7 while (tokenizer >> token) {
8 value.set(token);
9 context.write(value, IntWritable(1));
10 }
11 }
12};- Reducer Code Reducer class which extends class Reducer like that of Mapper. We define the data types of input and output key/value pairs and we aggregate the values in each of the list corresponding to each key and produce the final answer.
1class Reduce {
2public:
3 void reduce(Text &key, std::vector<IntWritable> &values, Context &context) {
4 int sum = 0;
5 for (IntWritable &x : values) {
6 sum += x.get();
7 }
8 context.write(key, IntWritable(sum));
9 }
10};- Driver Code In the driver class, we set the configuration of our MapReduce job to run in Hadoop. The given code snippet is specific to configuring a MapReduce job in Hadoop using Java. This type of code is typically not directly translated into other languages like JavaScript, Python, C++, or Go, as it is specific to the Hadoop Java API.
However, if you want to run similar MapReduce jobs in other languages, you would typically use a language-specific library or framework designed to interact with Hadoop or another distributed computing system.
1Configuration conf= new Configuration();
2Job job = new Job(conf,"My Word Count Program");
3job.setJarByClass(WordCount.class);
4job.setMapperClass(Map.class);
5job.setReducerClass(Reduce.class);
6job.setOutputKeyClass(Text.class);
7
8job.setOutputValueClass(IntWritable.class);
9job.setInputFormatClass(TextInputFormat.class);
10job.setOutputFormatClass(TextOutputFormat.class);
11Path outputPath = new Path(args[1]);
12
13FileInputFormat.addInputPath(job, new Path(args[0]));
14FileOutputFormat.setOutputPath(job, new Path(args[1]));The command for running a MapReduce code in Hadoop cmd prompt is:
_hadoop jar hadoop-mapreduce-example.jar WordCount /sample/input /sample/output_
1import java.io.IOException;
2import java.util.StringTokenizer;
3
4import org.apache.hadoop.conf.Configuration;
5import org.apache.hadoop.fs.Path;
6import org.apache.hadoop.io.IntWritable;
7import org.apache.hadoop.io.LongWritable;
8import org.apache.hadoop.io.Text;
9import org.apache.hadoop.mapreduce.Job;
10import org.apache.hadoop.mapreduce.Mapper;
11import org.apache.hadoop.mapreduce.Reducer;
12import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
13import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
14import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
15import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
16
17public class WordCount {
18
19 // Mapper Code
20 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
21
22 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
23 String line = value.toString();
24 StringTokenizer tokenizer = new StringTokenizer(line);
25 while (tokenizer.hasMoreTokens()) {
26 value.set(tokenizer.nextToken());
27 context.write(value, new IntWritable(1));
28 }
29 }
30 }
31
32 // Reducer Code
33 public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
34
35 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
36 int sum = 0;
37 for (IntWritable x : values) {
38 sum += x.get();
39 }
40 context.write(key, new IntWritable(sum));
41 }
42 }
43
44 // Driver Code
45 public static void main(String[] args) throws Exception {
46 Configuration conf = new Configuration();
47 Job job = Job.getInstance(conf, "My Word Count Program");
48 job.setJarByClass(WordCount.class);
49 job.setMapperClass(Map.class);
50 job.setReducerClass(Reduce.class);
51 job.setOutputKeyClass(Text.class);
52 job.setOutputValueClass(IntWritable.class);
53 job.setInputFormatClass(TextInputFormat.class);
54 job.setOutputFormatClass(TextOutputFormat.class);
55 Path outputPath = new Path(args[1]);
56 FileInputFormat.addInputPath(job, new Path(args[0]));
57 FileOutputFormat.setOutputPath(job, outputPath);
58 System.exit(job.waitForCompletion(true) ? 0 : 1);
59 }
60}Below, I'll provide a brief description of how you might approach a MapReduce word count task in each of the requested languages without translating the exact Java code.
JavaScript
In JavaScript, you could use a library like Hadoop-Streaming to run MapReduce jobs. A possible mapper and reducer written in Node.js might look like:
Mapper
1process.stdin.on('data', function(chunk) {
2 chunk.toString().split(/\s+/).forEach(word => {
3 console.log(word + "\t1");
4 });
5});Reducer
1var counts = {};
2process.stdin.on('data', function(chunk) {
3 chunk.toString().trim().split("\n").forEach(line => {
4 var parts = line.split("\t");
5 var word = parts[0];
6 var count = parseInt(parts[1]);
7 counts[word] = (counts[word] || 0) + count;
8 });
9});
10
11process.stdin.on('end', function() {
12 for (var word in counts) {
13 console.log(word + "\t" + counts[word]);
14 }
15});Python
Python provides Hadoop Streaming for MapReduce. You could write your mapper and reducer like:
Mapper
1#!/usr/bin/env python
2import sys
3for line in sys.stdin:
4 words = line.strip().split()
5 for word in words:
6 print(f"{word}\t1")Reducer
1#!/usr/bin/env python
2import sys
3
4current_word = None
5current_count = 0
6word = None
7
8for line in sys.stdin:
9 line = line.strip()
10 word, count = line.split('\t', 1)
11 count = int(count)
12 if current_word == word:
13 current_count += count
14 else:
15 if current_word:
16 print(f"{current_word}\t{current_count}")
17 current_word = word
18 current_count = count
19
20if current_word == word:
21 print(f"{current_word}\t{current_count}")C++
C++ doesn't have a direct equivalent for Hadoop MapReduce, but you could use MPI (Message Passing Interface) for parallel processing or find a specific library tailored for distributed computing.
Go
Similarly, Go doesn't have a direct MapReduce framework like Hadoop for Java. However, you could build a distributed system using Go's native concurrency features or use a library like Glow for MapReduce-style processing.
Please note that these examples are quite high-level and may require additional code, configuration, and dependencies to run in a real distributed environment.
Build your intuition. Click the correct answer from the options.
The last step of the MapReduce process is:
Click the option that best answers the question.
- Reducing
- Data Input
- Mapping
- Shuffle & Sort
Build your intuition. Is this statement true or false?
MapReduce programs have to be coded in Java.
Press true if you believe the statement is correct, or false otherwise.
Build your intuition. Fill in the missing part by typing it in.
The part of the MapReduce program where we set the configuration of our MapReduce job to run in Hadoop is called:
Write the missing line below.
One Pager Cheat Sheet
- To enable the efficient processing of large amounts of data,
MapReducewas created to help alleviate the difficulty of splitting data across multiple physical machines. - MapReduce is a programming paradigm that
splitsandmapslarge data sets into smaller chunks, processes them in parallel across commodity servers, and aggregates the data to return a consolidated output, providing benefits such as scalability, flexibility, speed and simplicity. - No, the Mapper step does not
shufflethe data, but instead it splits and maps it into key-value pairs before being further processed by the Map and Reduce functions. - Apache Hadoop is an ecosystem that enhances massive data processing, and is a popular choice in public cloud services such as
Amazon Elastic MapReduce,Microsoft HDInsightandGoogle Cloud Dataproc. - Using MapReduce, you can
tokenize,sort,shuffle, andreducethe unique words in an input file with a given value to create a new output file ofkey-valuepairs of the unique words and their occurrences. The MapReduce programcan be written in any language and can be divided into three main parts: a Mapper Code, Reducer Code, and a Driver Code, which sets the configuration of the program to be run in Hadoop using the commandhadoop jar hadoop-mapreduce-example.jar WordCount /sample/input /sample/output.- The last step of the MapReduce process is Reducing, where the data is aggregated and the output is computed by iterating over all values associated with a single key.
Hadoop Streamingallows MapReduce programs to be written in various languages such asPython,C++andRuby, and to parse theinput/output data formatas specified by the protocol.- The
Driver Codedefines the necessaryconfiguration settingsfor Hadoop to execute a MapReduce job efficiently, by assigning tasks to the workers in the cluster.
