

Persistent Storage layer
When designing persistent storage layers we need to pay more attention towards the following problems: dealing with large volumes of data and service reliability.
Suppose the requirement is to accommodate the storage for several hundreds of terabytes. Such volumes of data can not fit on a single server. Think about the kind of volumes large internet companies are working with. How can we deal with such volumes? Fortunately a number of solutions are already available for us to use.
Distributed file system and Large scale data stores Sharding is a process of splitting large data stores into smaller portions that can be hosted on a separate server. Sharding can be vertical or horizontal.
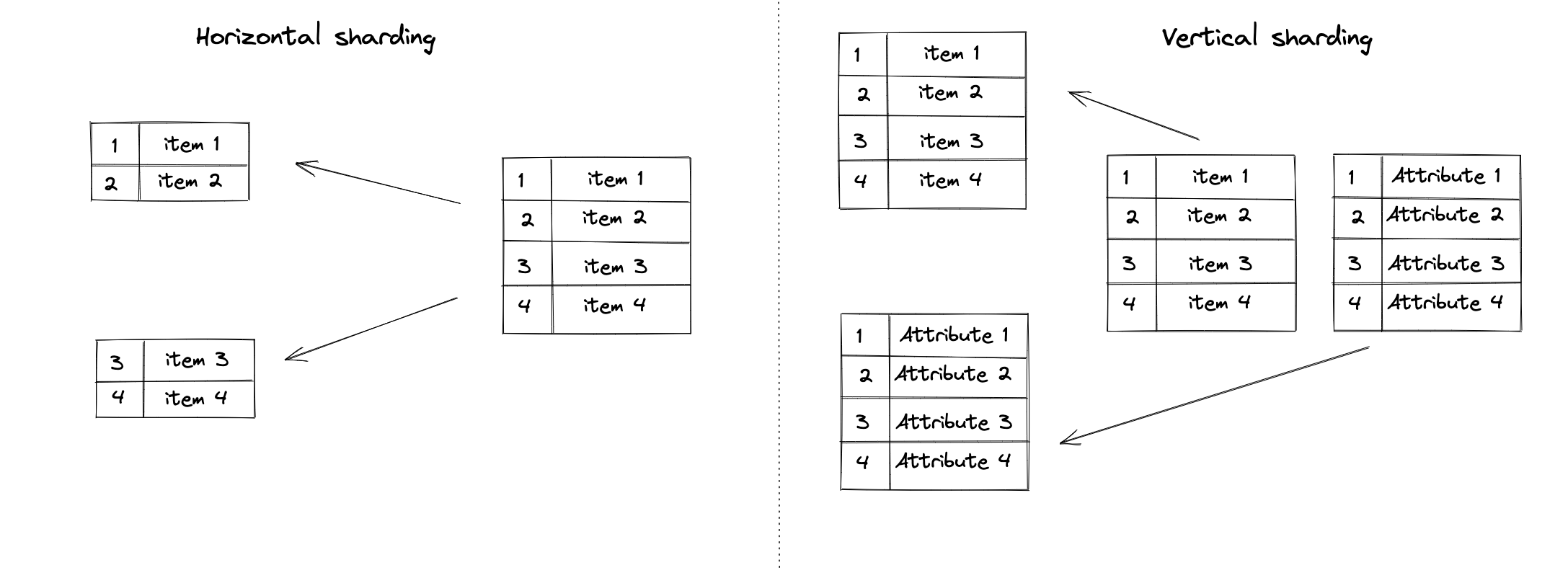
During vertical sharding we move tables to a separate host. This approach is often applied in relational data stores. Key value data stores partition a single table according to the number of servers in the cluster.
Distributed file system that allows to store any type of data. Internally such systems provide some level of ACID guarantees, however, there are caveats depending on the specific distributions that you are working with. Typically such storage systems would be used to store a mix of structured and unstructured data.
The next question you should be asking is: How can I find the data in the distributed file system quickly? The answer is large scale NoSQL key value data stores. You can think of them as an index on top of the distributed file system.
Putting everything together
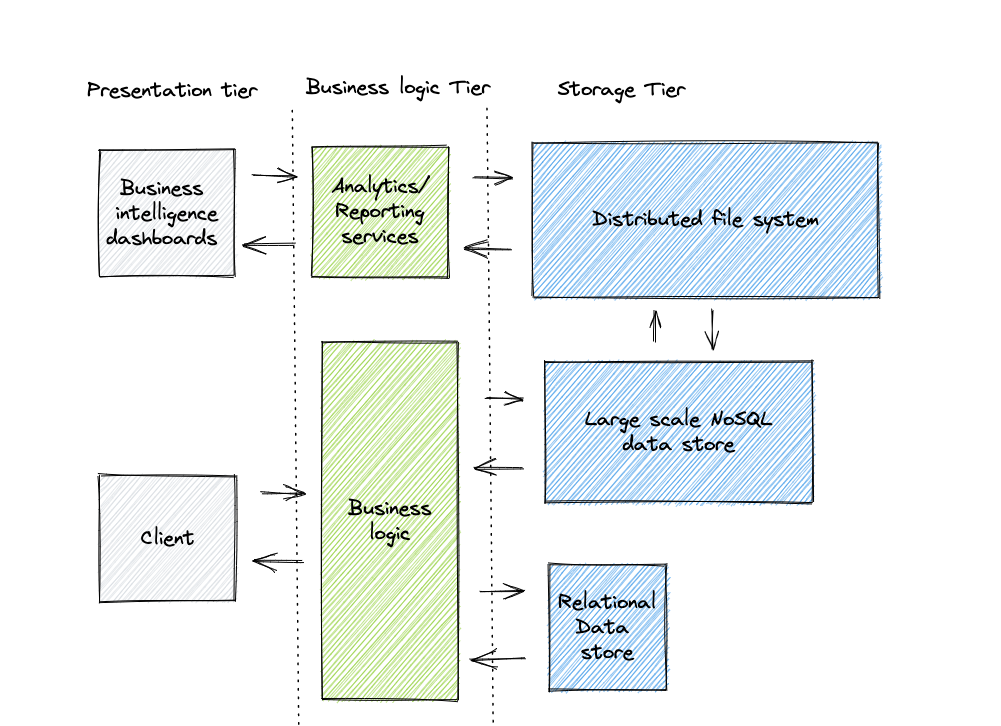
Overall a persistent storage layer consists of the following systems: A relational data store for the data that requires various ways of querying, A distributed file system for structured and unstructured data that needs to be preserved and occasionally analysed and a large scale key value data store that is can be set up to serve as an index for the data that is stored in a distributed file system. We can also add a cache layer to accelerate the performance of either data stores applying the principles described in the ephemeral storage layer section.
Large scale data stores seem like a great tool, why can’t we use them for everything? As mentioned at the beginning of this tutorial there is no single solution to fit all use cases. The following are the exact reasons why this would not be a good option:
- Lack of schema
- Lack of support for multi row transactions
- Higher latency with lower throughput compared to a relational database.
The first 2 reasons also apply to memory key value stores - quite often you will need multiple ways to query your data and searching the value by key would not fit every use case.