

What is Time-Series Data?
Data collected at several points in time is referred to as time-series data. This is different from cross-sectional data which looks at people, businesses, and other entities at a particular point in time. Correlations between observations are possible since data points in a time series are collected at neighboring periods. Time-series frequency refers to the frequency at which data is collected over a given period.
Time-series data have the following characteristics:
- Data is gathered over a set period.
- Workload data is created from scratch and written as inserts rather than being updated to replace existing data.
- When data is written, the most current time interval is automatically allocated to it.
Processing time-series data involves 5 different steps as shown below:
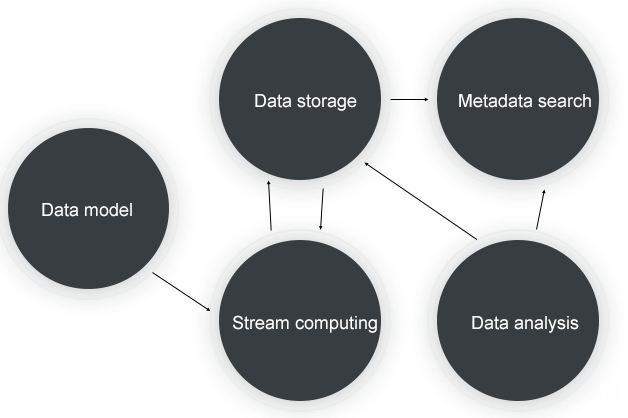
Data model: The gathered time-series data must comply with the model's specification, including all of the time series data's characteristic qualities.
Stream computing: This step is for pre-aggregation, downsampling, and post-aggregation for the time series data available.
Data storage: The storage system allows the separation of cold and hot data and efficient range queries. Additionally, the system offers high throughput, vast volume, and low-cost storage.
Metadata retrieval: This step involves supporting several retrieval methods such as those to store and retrieve timeline metadata in the tens of millions to hundreds of millions.
Data analysis: The last step analyzes and computes time-series data in real-time.