Key Strategies for Data Partitioning
Some commonly used techniques to determine data placement across partitions:
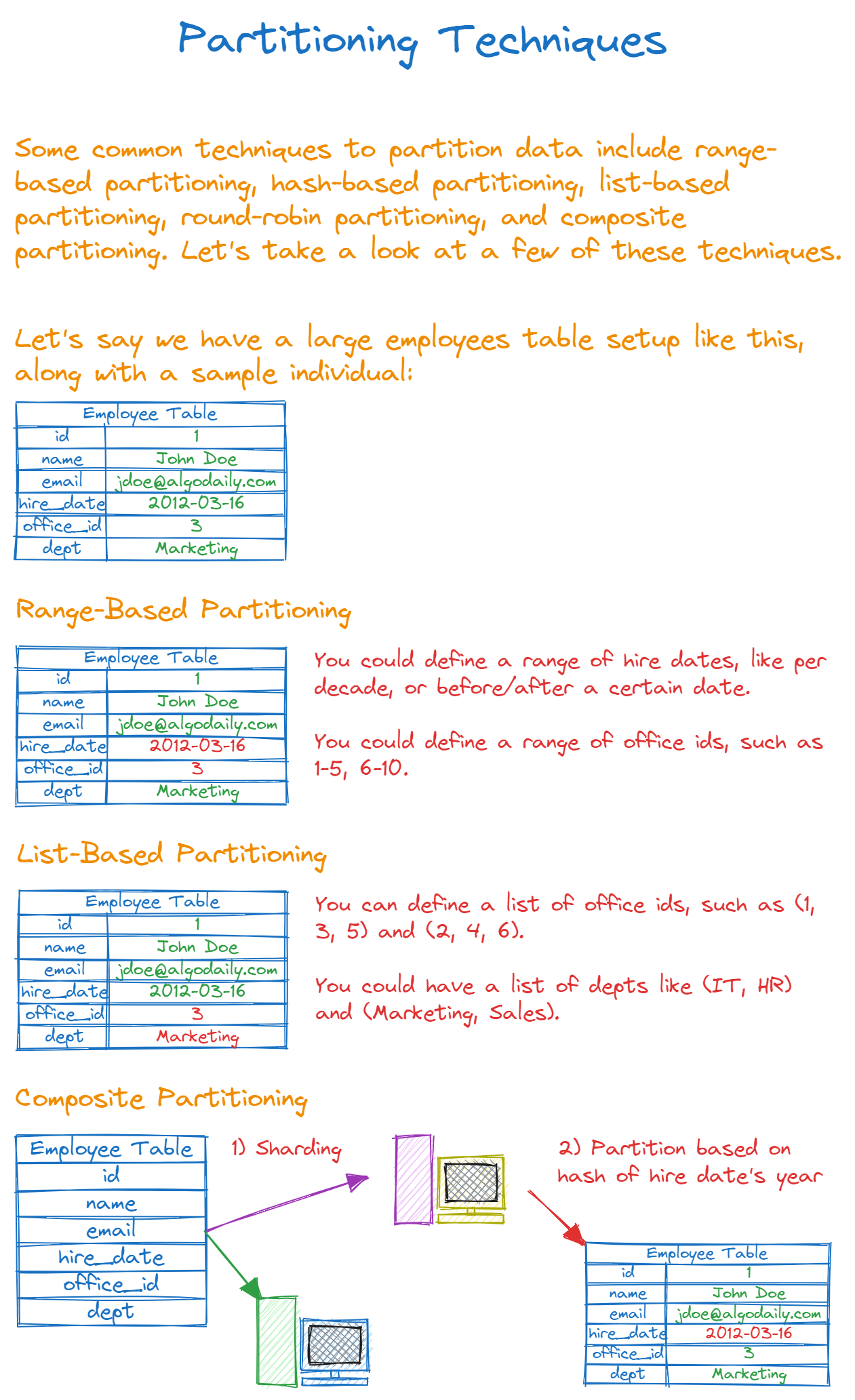
Range-Based Partitioning
Data is partitioned based on ranges of the values of a column like date or timestamp. For example, a table of sales data may be partitioned by date so that each partition contains one year of sales data.
Hash-Based Partitioning
A hash function is applied to some key or column to determine the partition where a particular data item will reside. For example, if we hash-partition a users table based on user_id, all users with the same hash(user_id) will be in the same partition.
Re-balancing loads across partitions is easy since the hash function doesn't change. The problem arises when the hash function results in skew.
List-Based Partitioning
Each partition is assigned a list of values, and any record whose partitioning key exists in the list will be stored in that partition. For example, data centers can be used to list-partition customer data based on regions.
Round-robin Partitioning
Data is distributed sequentially among available partitions as it comes in. It provides uniform data distribution but querying becomes complex without a lookup directory.
Composite Partitioning
Combinations of partitioning techniques can be applied. For example, first horizontally sharding a table then range-partitioning each shard further improves scalability.