


H. SQL Indexing
1. What is an Index?
Indexes are used to retrieve data from the database quickly, similar to the index of the back of a book. It speeds up the operation of accessing data from a database tables at the cost of additional time since when updating tables indexes too need to be updated.
Looking at the sequential search (table scan) below we can see how time consuming it is to search all records before we get to our desired record.
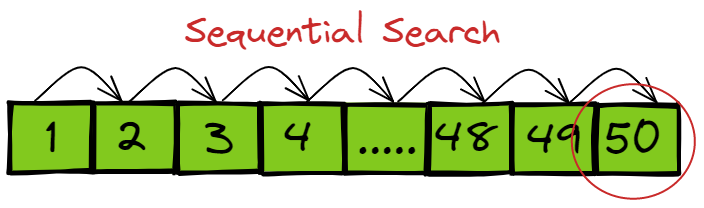
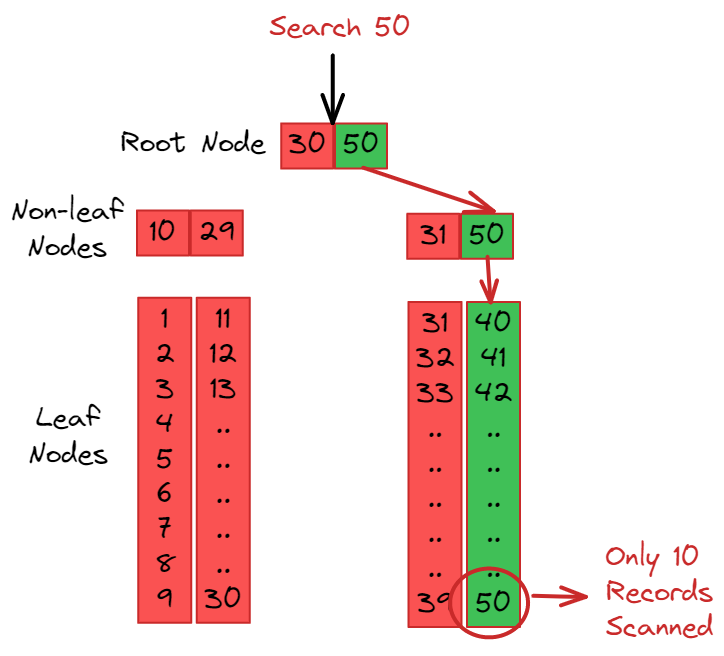
By creating a tree structure we increase search performance by minimizing the scanning of the records, as from the example below only 10 records are scanned and all other records are bypassed.
1-- Create an index
2CREATE INDEX index_name
3ON table_name (column_1);
4
5-- Multiple column index
6CREATE INDEX index_name
7ON table_name (column_1, column_2);
8
9-- Drop the index
10DROP INDEX index_name; 2. What is the difference between Clustered and Non-clustered index?
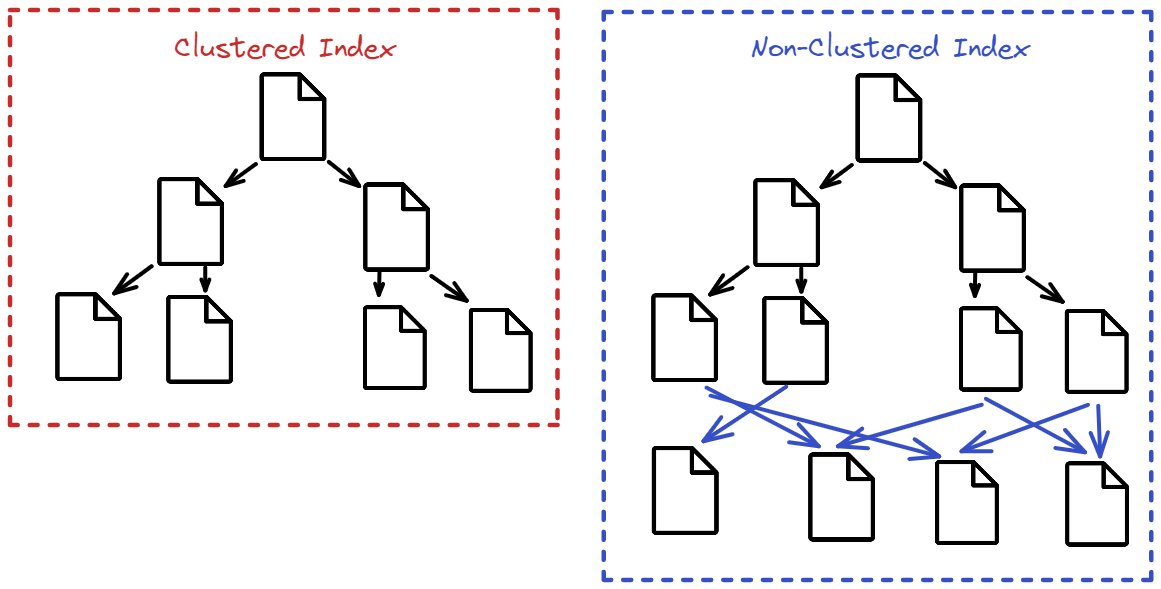
Clustered Indexes are sorted as trees, the actual data is stored in the leaf nodes. This type of indexing reorders the way records in the table are physically stored thus a table can only have one clustered index but it is faster than non-clustered indexing.
Non-Clustered Indexes on the other hand is where the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non-clustered index does not consist of the data pages, instead they contain pointers like page numbers in the index of a book. This type of indexes are created on top of the actual data. Unlike clustered indexing a table can have more than one non-clustered index.