Autodiff: Why Gradients Matter
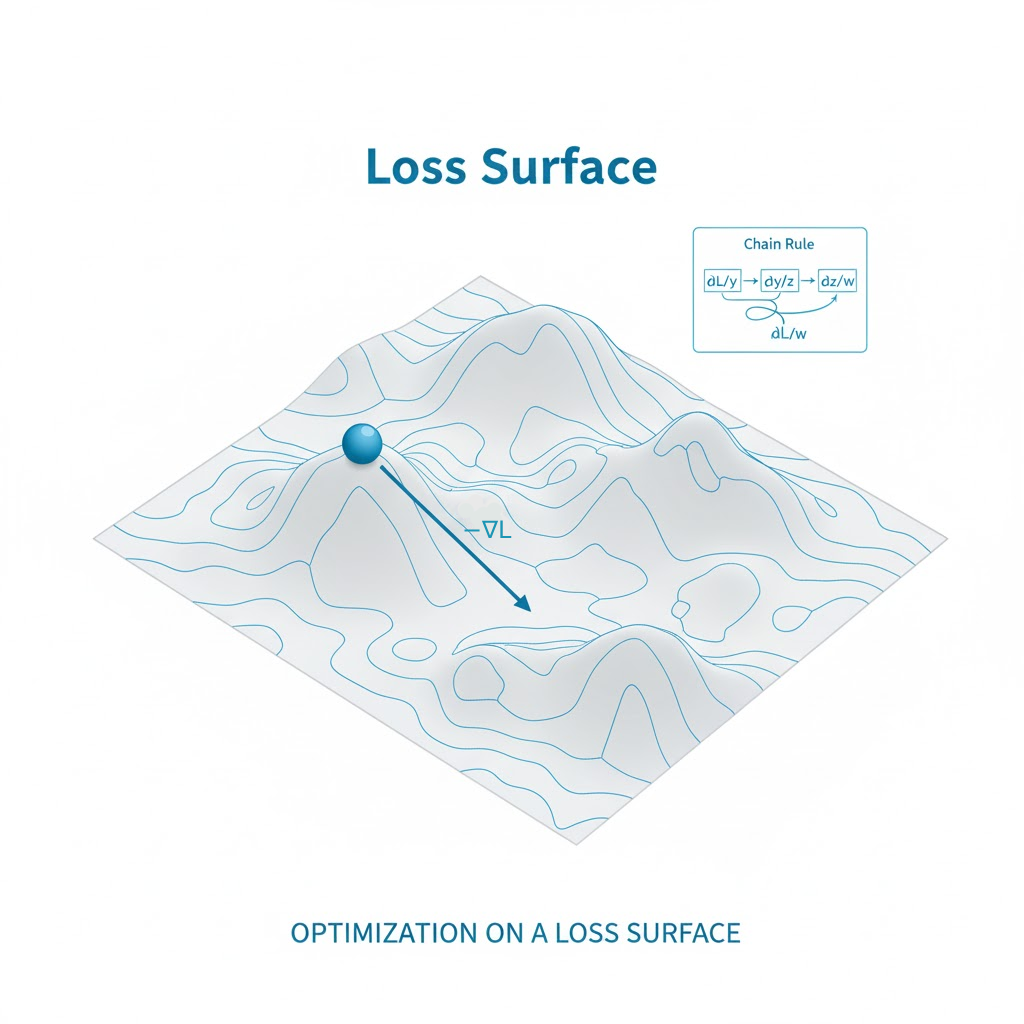
Automatic differentiation (autodiff) uses the chain rule to compute how changing each weight will change the loss. Forward: compute predictions. Backward: propagate ∂loss/∂node from outputs to inputs, accumulating gradients.
Without gradients, your model can’t learn. With them, an optimizer updates variables:
w ← w − η * ∂L/∂w where η is the learning rate.