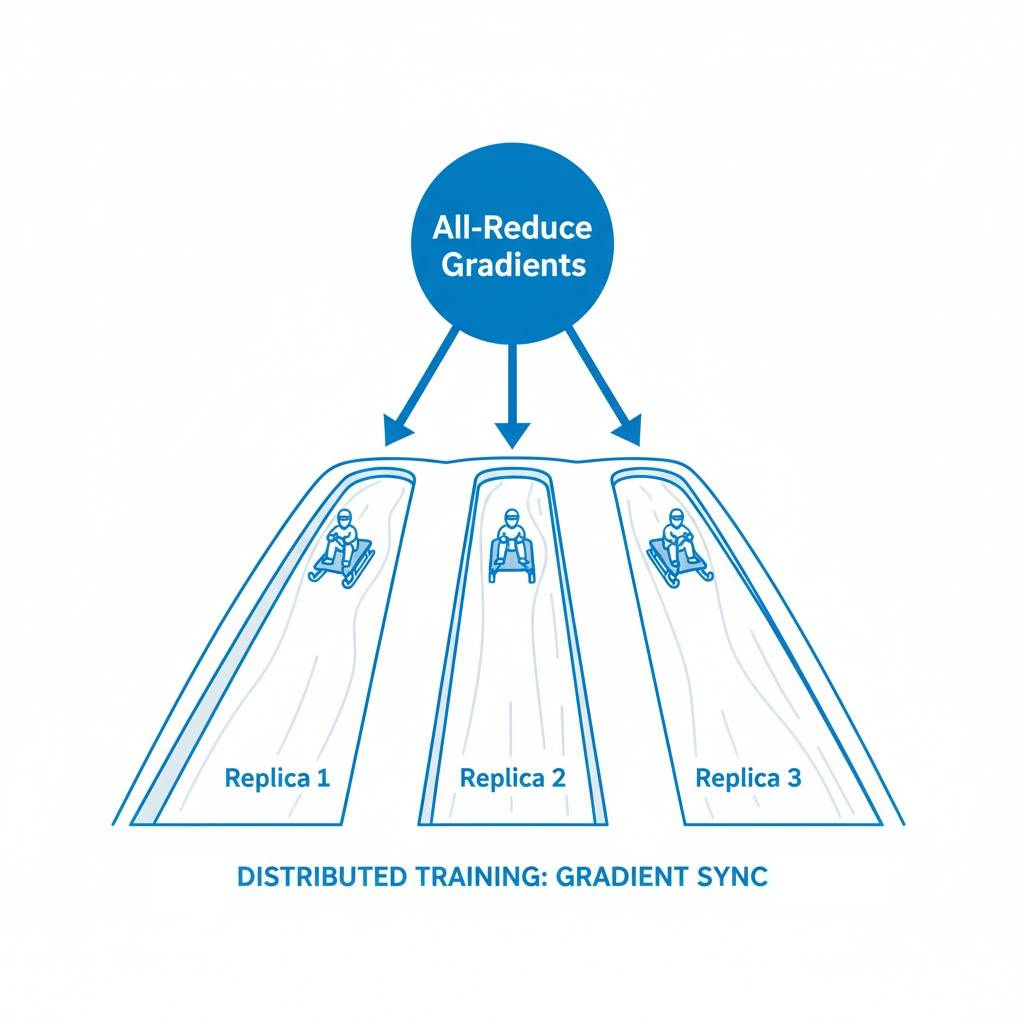
Distribution Strategies: Use All the Compute
tf.distribute.Strategy scales training across multiple GPUs/TPUs or machines. It shards your batches, runs replicas in parallel, and reduces gradients correctly (e.g., all-reduce).
Mental model: many workers push identical sleds uphill (same model) on different snow lanes (data shards), then share what they learned at checkpoints.